
Iedereen maakt fouten – post-mortems en Zwitserse kaas
Ik geef je een aantal voorbeelden, waarbij ik je bijspijker over wat psycholoog James Reason ons over fouten aan het verstand probeert te peuteren en wat je zou kunnen doen als jij voor een softwareramp komt te staan. Alle tekenen wijzen er namelijk op dat het ook jou een keer zal overkomen…
Smullen van post-mortems
Recent kwam ik deze post-mortem tegen. Een junior developer vindt in zijn onboarding document uitleg over hoe hij zijn lokale omgeving werkend kan krijgen. Helaas stonden er in dat document waarden die naar de productie database verwezen. Dus toen hij zijn testscript ging draaien waarbij de ‘testwaarden’ tussendoor werden gewist, wistte hij productiedata. Er waren geen back-ups. Hij werd op staande voet ontslagen.
Ook lees ik regelmatig posts in de trant van: ‘‘Op een druilerige dinsdagochtend werd een standaard commando uitgevoerd om een kleine release naar productie uit te rollen toen het noodlot toesloeg.” Programmeur X doet dit bijna dagelijks, maar blijkbaar is dit toch niet een dag als alle andere! Een mooi voorbeeld hiervan vind je aan het begin van deze post-mortem of in deze quote van Google: “At 14:50 Pacific Time on April 11th, our engineers removed an unused GCE IP block from our network configuration, and instructed Google’s automated systems to propagate the new configuration across our network. By itself, this sort of change was harmless and had been performed previously without incident.” (bron).
Soms kun je een tijdslijn volgen waarin je elke (mislukte) toetsaanslag en gevallen zweetdruppel kunt lezen van dit rampscenario. Bekijk bijvoorbeeld deze post-mortem van GitLab, die je meeneemt naar de plaats delict. Vaak lees je ook nog wat de programmeurs van deze ellende hebben opgestoken, zodat je weet dat ze deze fout in elk geval niet herhalen. Deze lessons learned vind je mooi omschreven in deze post-mortem van Amazon.
Mosterd na de maaltijd
Het lezen van post-mortems die comments toestaan vind ik zelf het meest interessant. Er zijn altijd mensen die dan denken: dit had mij ook kunnen overkomen. Of die hun respect tonen (hugops). Weer anderen komen achteraf met prachtige suggesties voor hoe programmeur X het beter of handiger had kunnen aanpakken (heerlijk, die mosterd na de maaltijd!). Bij enkele van de comments wordt zelfs gesproken over het ‘straffen’ van de daders. In de reacties onderaan deze post-mortem van Digital Ocean komen bovenstaande voorbeelden in veelvoud voor. Er ontstaat zelfs een hele discussie over wie er nou precies verantwoordelijk is voor de gemaakte fouten…
Hoe kon het bij deze en andere developers zo vreselijk misgaan? Soms laat hardware het afweten. Dan kun je de techniek de schuld geven. Maar hoewel dat op zichzelf een prima verklaring is in sommige gevallen (‘hij is gewoon stukgegaan’) zit er volgens mij nog meer achter. Vooral na het lezen van de post-mortem van Digital Ocean kreeg ik een flashback naar een van mijn favoriete vakken tijdens mijn studie: ‘human error’. Ik kijk daarom graag naar de menselijke kant of invloed van de mens als ik zo’n verhaal lees. Er wordt namelijk (falende techniek buiten beschouwing gelaten) snel gedacht in termen van ‘DE schuldige’, terwijl de theorie en het bestuderen van juist deze post mortems leert dat dit nooit slechts door één enkel individu of incident komt.
Een stukje theorie over menselijk falen
James Reason is een professor in de psychologie die een theorie heeft ontwikkeld over human error: fouten die ontstaan door menselijk handelen. Zo maakt hij onder andere een onderscheid tussen een persoonlijke en systematische benadering van menselijke fouten. Bij een persoonlijke benadering wordt er op de man gespeeld: hij of zij zal wel iets vergeten zijn, niet goed hebben opgelet of het interesseerde die persoon niet genoeg om het goed te doen. Denk aan een dokter die een medische fout maakt: we zijn geneigd een individu dan flink te straffen. Men probeert dit soort persoonlijke fouten te voorkomen door mensen bang te maken voor de gevolgen zoals dreigen met ontslag en reputatieschade.
In het voorbeeld van de developer die een tutorial volgde en vervolgens een productiedatabase wistte doet de CTO alsof het wissen van de database een persoonlijke fout is van deze specifieke developer, en wordt hij dus veroordeeld met ontslag volgens de persoonlijke benadering van de gemaakte fout. Dit is gek, het lijkt namelijk eerder het falen van een heel systeem zoals in de reacties onder zijn verhaal ook wordt gesuggereerd.
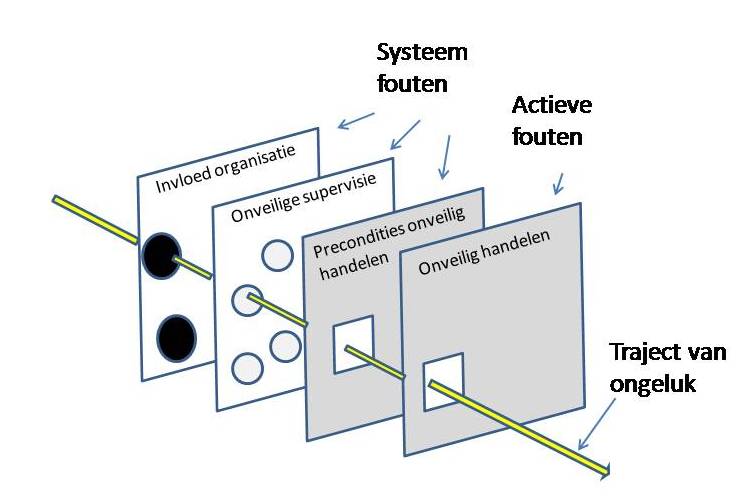
Systematische benadering: ‘Zwitsersekaasmodel’
Deze conclusie komt ook naar voren in de systematische benadering. Hierin wordt er gekeken naar de werkomstandigheden waarin mensen werken. Voor het hele systeem als geheel (dus zowel voor de mensen als voor de techniek) probeer je verdedigingsmechanismen in te bouwen. Je probeert hiermee fouten te voorkomen of de schade van een fout te beperken. James Reason illustreert de systeembenadering met zijn ‘Zwitsersekaasmodel’.
Binnen de systematische benadering van fouten nemen verdedigingsmechanismen een grote rol in. Deze zijn over het algemeen gelaagd ingericht. Denk aan een eerste technisch ingerichte verdedigingslaag: alarmen, automatische uitschakelingen van systemen, fysieke barrieres om niet makkelijk bij een ‘killswitch’ te kunnen komen. Een andere laag is weer afhankelijk van mensen die met het systeem werken. Denk hierbij aan specialisten zoals DevOps-medewerkers. Ook kun je een verdedigingslaag inrichten door procedures of administratieve checks te introduceren (Definition of Done, checklists bij user stories). Maar alle verdediging ten spijt, er kan altijd nog iets misgaan…
In een ideale wereld is elke laag perfect en komen er geen fouten doorheen. In de echte wereld lijkt een laag meer op een plakje Zwitserse kaas: vol met gaten. Een gaatje in een enkele laag zal niet zo veel gevolgen hebben, er zijn immers nog andere lagen waarin een fout kan worden opgemerkt. Maar in tegenstelling tot echte kaas, kunnen de gaten in de verdedigingslagen verschijnen en verdwijnen. Hierdoor kan het gebeuren dat op een bepaald moment alle gaten precies op één lijn liggen. Een fout kan zo onbedoeld door alle lagen heenpiepen en tot uiting komen. Dit is dus precies de reden dat er ook bij jou(w bedrijf) zeker weten een keer iets fout zal gaan!
Wat kun je zelf doen?
Het is belangrijk om je te realiseren dat elk systeem, met hoeveel controlemechanismen ook, altijd kans heeft dat iets een keer fout gaat. Het is dus niet een kwestie van ‘hoe voorkom ik de fout’, maar dat wanneer het mis gaat
- je zo snel mogelijk probeert datgene wat er fout gaat te stoppen.
- je zo snel mogelijk (intern) aangeeft dat er iets misgaat/is gegaan. Vraag dus om hulp en probeer vooral niet je fout te verdoezelen. Zoals je hebt kunnen lezen is een fout die via jou tot uiting komt (tenzij je het expres doet), niet alleen jouw fout!
- je als de acute nood voorbij is en de schade hersteld is kijkt hoe het zo ver heeft kunnen komen.
- je bedenkt wat je zelf, maar zeker ook aan het systeem, kunt veranderen waardoor in elk geval het risico op deze en soortgelijke fouten vermindert. Handig hulpje: in 2012 hebben wetenschappers gewerkt aan een taxonomie voor het identificeren van verschillende soorten ‘menselijke factoren’. Lees de paper voor meer informatie.
- introduceer een nieuw controlemechanisme voor die specifieke fouten.
Als het goed is hebben jij en de rest van je bedrijf van deze fout geleerd, hoera! Laat het nu los. Je bent tenslotte ook maar een mens.