
Automatisch code comments bijwerken met large language models: deel 2
Bij Infi kijken we altijd hoe nieuwe technologie ons kan helpen betere software te schrijven. Dat is ook een van de manieren waarop we naar AI kijken. Quinten en Stef lopen stage bij Infi Nijmegen en bekijken of AI kan helpen met het up to date houden en het verbeteren van de kwaliteit van commentaar in code met AI. In deze blog geeft Quinten ons een update over hun project.
Waar waren we ook alweer mee bezig?
Er is een probleem. Commentaar raakt out-of-date met code updates, maar dit valt developers pas laat op. Vaak zit de context van de code zo goed in het hoofd van een developer dat diegene zelf het commentaar niet meer leest. En als een developer erachter komt dat het commentaar niet meer klopt, is er opnieuw een redelijk grote kans dat hij vergeet om dat commentaar, na zijn begrip van de code te hebben opgebouwd, bij te werken.
Wij dachten: dat kan AI vast beter.
Ons doel is om met AI de kwaliteit van commentaar in code niet alleen te handhaven, maar ook te verbeteren.
Dus we zijn begonnen met onderzoeken of large language models (LLM’s) intelligent genoeg zijn om commentaar te updaten, maar niet alleen dat… Het LLM moest ook vaststellen of het commentaar nog up-to-date was met de code. Dus er zijn eigenlijk meerdere dingen die het LLM moest kunnen:
- Context van de code snappen
- De context weten te linken aan de comment
- Eventuele fouten in het commentaar die niet overeenkomen met de code aanpassen
We hadden hierbij als uitgangspunt dat de code altijd correct was. Our single source of truth. Daarnaast was het niet de bedoeling om deze AI nieuw commentaar te laten genereren, of om commentaar weg te laten halen. Dit zou de scope van het onderzoek te groot maken.
Aan de hand van dit vraagstuk is een onderzoek opgesteld met als hoofdvraag:
Hoe verandert een AI-tool de tijdsbesteding bij comment-updates?
Om de vraag te beantwoorden zouden we deelnemers van het onderzoek 2x 15 minuten commentaar in een repo laten verbeteren. 1x zonder AI, en 1x met hulp van onze eigen AI-tool.
De AI-tool zou de code analyseren en verbeterd commentaar voorstellen. De deelnemers zouden vervolgens een simpele merge-view te zien krijgen zoals je ook wel kan vinden in webapplicaties zoals Gitlab, Github en apps als GitKraken en de Jetbrains IDE’s. In die view konden de deelnemers van het onderzoek kiezen voor de oude, nieuwe of een combinatie van beide soorten commentaar. Daarna was er nog de mogelijkheid om de tekst aan te passen.
Wat is er veranderd sinds artikel 1?
Tijdens het schrijven van artikel 1 waren we nog overtuigd van de open-source Llama modellen. Ondertussen achten wij de kans klein dat die modellen intelligent genoeg zijn om onze taak consistent succesvol te kunnen voltooien. Misschien dat het was gelukt met een heleboel geavanceerde technieken, maar we hadden niet de tijd om deze technieken meester te maken én ze toe te passen, dus we moesten op zoek naar een alternatief. De keuze is daarbij gevallen op GPT-4. Nu hadden we ook nog geluk bij het maken van deze keuze. Kort na de overstap kwam OpenAImet een turbo update voor GPT-4, waardoor hij niet alleen beter maar ook sneller was dan de Llama modellen. Daarnaast heeft OpenAi gezorgd dat de context die de ChatGPT modellen snappen nu veel groter is: 128k tokens wat neerkomt op ongeveer 300 bladzijden tekst. De maximale grootte van de output tekst is wel wat kleiner met maximaal 4096 tokens, wat neerkomt op ongeveer 10 bladzijden.
Prompt engineering
Een van de grootste problemen bij de Llama modellen was het duidelijk maken van het probleem. Deze aanpak heeft als doel om met AI de kwaliteit van commentaar in de code te verhogen door de relevantie en nauwkeurigheid van commentaren te verbeteren. We hebben honderden verschillende combinaties van woorden en syntaxen gebruikt om deze modellen hopelijk duidelijk te maken dat ze geen commentaar mochten toevoegen of verwijderen, en dat ze vooral ook de code niet aan mochten raken.
Dit is uiteindelijk niet gelukt. Geen van al die dingen.
GPT-4 had vooral moeite met snappen dat hij geen nieuw commentaar toe mocht voegen. Eigenlijk hadden we, zodra we GPT-4 in gebruik namen, bruikbaardere responses waar we verder mee konden developen. Een voorbeeld daarvan is dat we hem vroegen om zijn verbeterde commentaar in response blokken neer te zetten met een method/class signature waar het commentaar bij hoorde.

Het niet toevoegen van commentaar was een uitdagendere taak. We hebben dit op tientallen manieren geprobeerd uit te leggen, maar dat was ook onze fout. Sommige dingen kan je beter laten zien, net zoals bij de output formatting hierboven.
We zijn dus begonnen met het creëren van commentaar met daarin aangegeven waar een commentaar update van het LLM wel of niet mocht staan.
Na een paar van dit soort voorbeelden begreep de AI het.
Een groot aantal fouten in het commentaar detecteerde GPT-4 gelijk, maar er waren ook overduidelijke fouten die het LLM compleet miste.
Zo hadden we ergens dit commentaar neergezet:
“Delete positions for a specific device if today is a Wednesday”
Het goede commentaar zou er zo uit zien:
“Delete positions for a specific device”
In de code was verder niets te vinden over een datum of dag. Een programmeur zou met een korte blik op de code al zien dat het commentaar fout was.
Na de les die we hadden geleerd over het [Good][Bad] patroon leek het een goed idee om met een soortgelijk patroon aan te geven welk commentaar fout is. Niet voor iedere mogelijke fout, maar het soort fouten waar het LLM moeite mee had.
Er werden meerdere stukken code in de prompt geplaatst met TODO’s eraan toegevoegd met daarin het juiste antwoord.
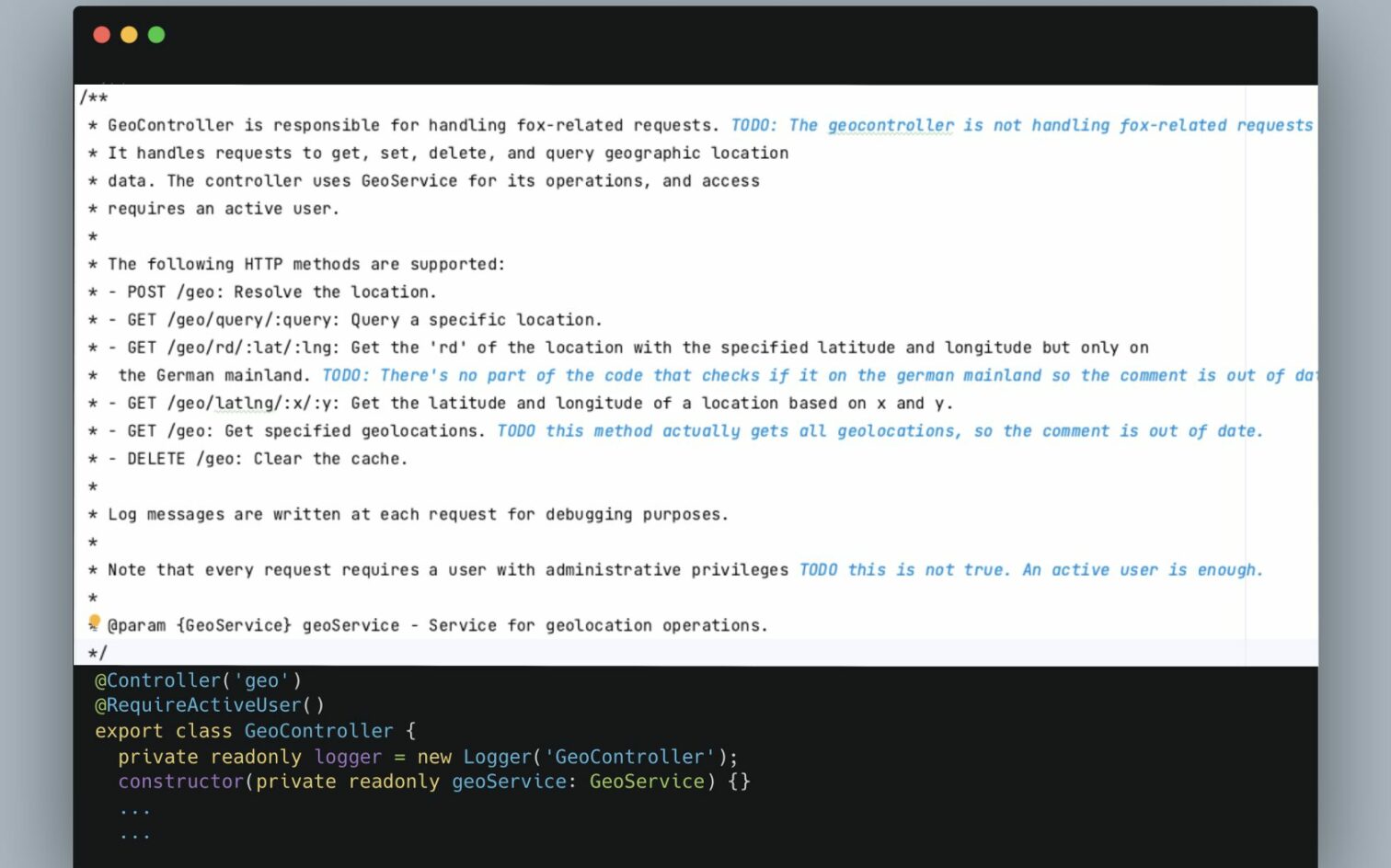
De volledige prompt, die voor ieder bestand gebruikt werd is te groot voor dit artikel. Hij bestaat op dit moment uit minimaal 249 regels. Hierbij moet je eigenlijk ook nog de code toevoegen, dus een uiteindelijk prompt is al snel 500 of meer regels.
Resultaten onderzoek
Zeggen dat we met onze mega prompt goede resultaten hebben behaald zegt niet echt veel, dus laten we kijken naar de data van ons onderzoek.
Ons onderzoek ging vooral over de tijdsverschillen van tijdsbesteding van de deelnemers, maar we kwamen er al snel achter dat die tijdsbesteding niet heel erg veranderde. Het zoeken naar en vinden van commentaar duurde bij deel 2 zelfs langer, maar dat kwam door de toen nog gebrekkige UI van onze AI-tool.
| Categorie | Deel 1 | Deel 2 |
|---|---|---|
| Gemiddelde Tijd voor Context en comments Begrijpen (min:sec) | 11:20 | 10:27 |
| Gemiddelde Tijd voor comments Zoeken (min:sec) | 00:50 | 01:52 |
| Gemiddelde Tijd voor Aanpassing/Toepassing van comments (min:sec) | 02:16 | 01:06 |
Wat wel opviel waren de metrics die niet per se direct binnen het onderzoek pasten. Aangezien de AI gemiddeld 10 minuten deed over zijn analyse van de bestanden in ronde 2, en de deelnemers van het onderzoek hier 15 minuten voor kregen, hebben we eerst de resultaten genormaliseerd naar 10 minuten.
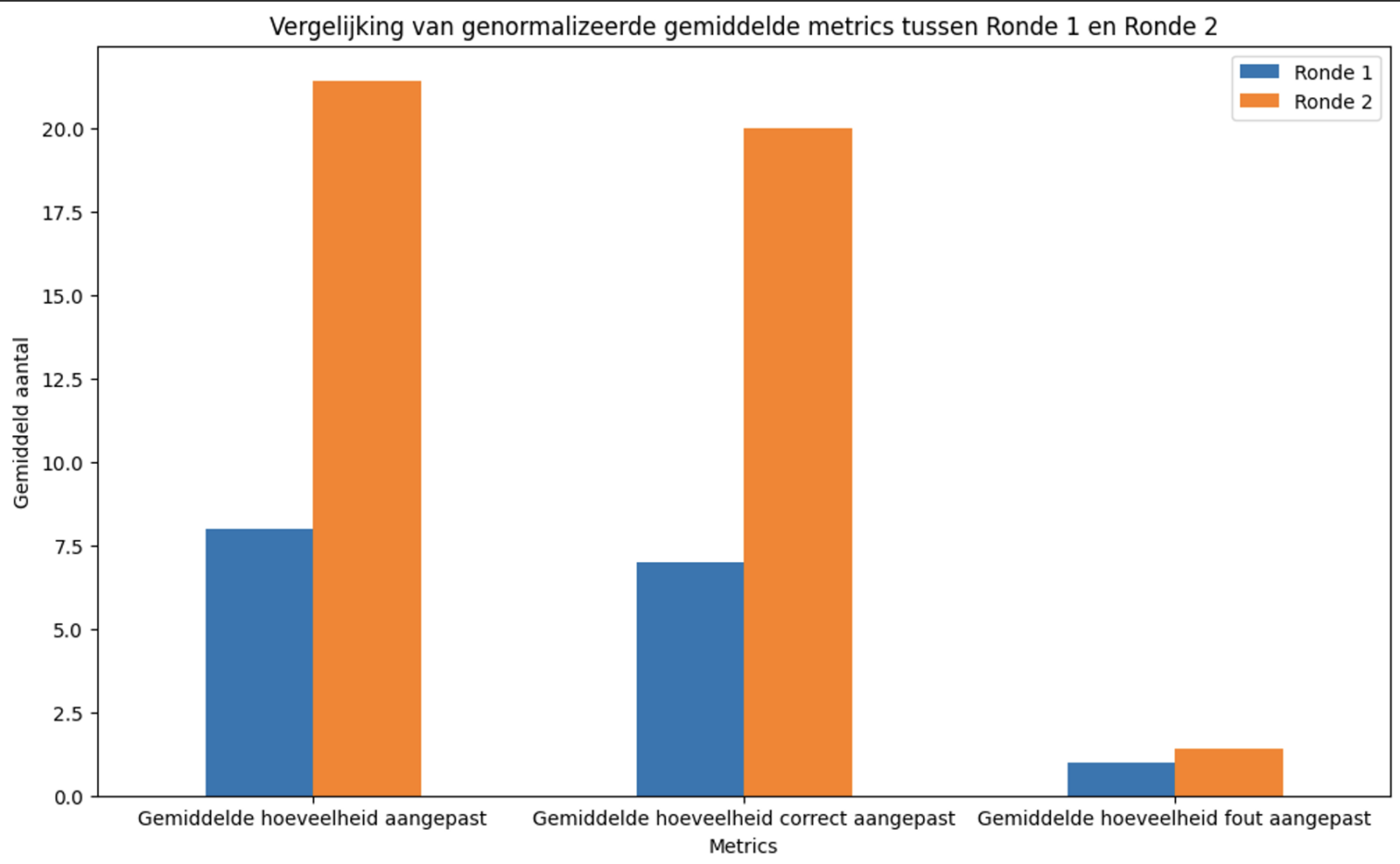
Uit de bovenstaande afbeelding leek te kunnen worden afgelezen dat de AI-tool een erg positieve invloed had op de kwaliteit van het commentaar. De AI-tool was echter alleen geprogrammeerd om bestanden weer te geven waar het AI ook aanpassingen had voorgesteld. Als de AI dus geen fouten vond in het commentaar van een bestand, was dat bestand ook niet zichtbaar in de tool.
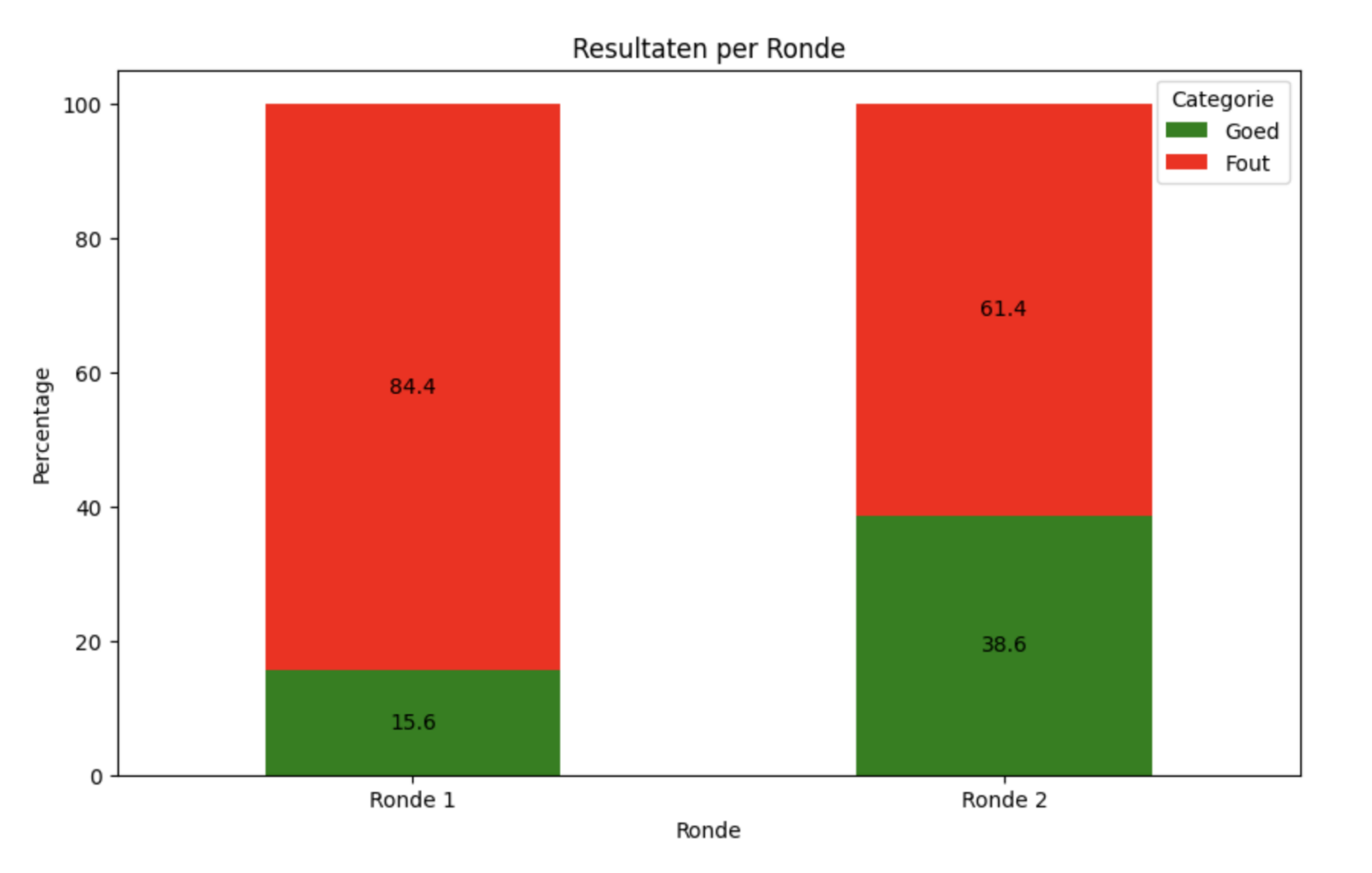
Dus we hebben hierna gekeken naar alle fouten in alle bestanden. De data hierboven bevat de data van ronde 1 en 2. Bij ronde 1 omvatte ‘fout’:
- Niet geopende bestanden waar wel fout commentaar in zaten
- Fout verbeterd commentaar
- Fouten die deelnemers hadden gemist.
In ronde 2 omvatte ‘fout’:
- Fout gevonden commentaar
- Niet gevonden commentaar
- Fout verbeterd commentaar
‘Goed’ omvat voor beide balken:
- Goed gevonden en goed verbeterd
- Fout gevonden en goed verbeterd
De AI had het voordeel dat na 10 minuten alle bestanden waren behandeld. In ronde 1 hadden de deelnemers gemiddeld 10.6% van de bestanden aangeraakt. We kunnen dus stellen dat de AI effectiever is omgegaan met de gegeven tijd, en ook veel goedkoper is dan een developer 15 minuten (of in de praktijk waarschijnlijk langer) commentaar laten verbeteren. Het is ook duidelijk dat er nog heel veel ruimte is voor verbetering, want slechts 40% van de AI’s resultaten zijn goed.
De grootste verbetering die de AI-tool nu moet krijgen is dat hij minder fouten compleet mist. Een fout onjuist verbeteren is niet zo’n groot probleem als fouten compleet missen. De resultaten tonen wel aan dat de inzet van AI significant bijdraagt aan de verbetering van de kwaliteit van codecommentaar.
Toekomst van de AI-tool in Codecommentaar Verbetering
Wij denken dat met deze resultaten gezegd kan worden dat LLM’s kunnen helpen bij het bijwerken van commentaar. Dit maakt meer tijd voor leukere taken zoals programmeren en programmeren en natuurlijk programmeren: daadwerkelijk bouwen aan features waarmee we gebruikers helpen.
De vraag is hoever we de kennis van LLM’s kunnen pushen zonder zelf een custom model te maken. Hoe intelligenter de prompt wordt opgesteld, hoe intelligenter het LLM kan reageren, maar met nieuwe updates van OpenAi komen ook hier nieuwe mogelijkheden. Ons uiteindelijke doel is om met AI de kwaliteit van commentaar in code blijvend te verbeteren, wat zomaar een revolutie teweeg kan brengen in softwareontwikkeling.
Als het LLM weet dat het context mist over een stuk code, en zoals een ontwikkelaar ‘door wil klikken’ op een functie om de definitie te bekijken, zouden we dat mogelijk kunnen maken met LLM-actions. LLM-actions maken het mogelijk voor LLM’s om een REST API aan te spreken. Met de juiste gegevens zou de API de juiste definitie terug kunnen geven, en daarmee de context van het LLM live uitbouwen voor een nog beter begrip van de code.
Het probleem wat we nu al voorzien met deze actions, is dat je nooit volledige invloed hebt over hoe het LLM iets interpreteert (eigenlijk net als dat je nooit weet hoe iemand je whatsapp berichten interpreteert), en dus ook niet over hoe consistent hij een action zal gebruiken. Er zijn meerdere van dit soort “ik kan niet met 100% zekerheid voorspellen wat er gaat gebeuren” situaties bij het gebruik van LLM’s.
Finetuning
Finetuning is ook een optie. Finetuning kan ervoor zorgen dat een LLM consistentere outputs levert. Dit doe je door een dataset aan te leveren met voorbeeld inputs en outputs.
Hier gaat wel heel veel onderzoekwerk in zitten, maar zou de resultaten wel naar nieuwe hoogtes kunnen pushen.
RAG
De laatste techniek is RAG. Retrieval-augmented generation. Je bouwt een vector database met kennis en het LLM zoekt deze database door naar de benodigde informatie bij iedere request. Op dit moment denken wij niet dat deze techniek voor deze AI-tool iets zou opleveren, maar wie weet op wat voor ideeën we komen in de toekomst…
Laatste woorden
AI kan een belangrijke bijdrage leveren bij het verbeteren van commentaar, maar zoals we zien op basis van andere AI-projecten (youtube.com) die nu vaart beginnen te krijgen, is het waarschijnlijk beter om een combinatie te maken van traditionele programmeer technieken en analyse en daarbinnen een AI specifiek vragen te stellen en het niet aan de AI overlaten om het geheel te interpreteren. Naar verwachting zal dat leiden tot snellere en betere resultaten.

