Schalen in drie dimensies – deel 1: Microservices en message queues
Schaalbaarheid van applicaties is een lastig probleem, en ook iets wat vaak niet één oplossing heeft. In dit eerste deel gaan we kijken naar de termen die misschien wel het meest voorkomen zodra het over schalen gaat: microservices en message queues.
Bij Infi hebben we een aantal projecten gedaan waar we tegen limieten aanliepen van wat de bestaande code en architectuur aankon, maar daar ook altijd mooie oplossingen voor bedacht. Hoe we dat gedaan hebben, en wat we daarvan geleerd hebben lees je in deze serie blogposts.
Meet: Tracey
Tracey is een customer service automation platform dat grote hoeveelheden tracking data van pakketten analyseert om zo slimme monitoring aan te bieden en voorspellingen te kunnen doen. Tracey integreert met veel verschillende post- en pakketbedrijven waar die data vandaan komt. Die data wordt in hun eigen systeem geladen, waar vervolgens allerlei analyses uitgevoerd kunnen worden.
Het probleem
Tot nu toe klinkt het simpel genoeg: haal data op uit externe systemen, en analyseer het. Echter, er zijn hier twee grote moeilijkheden. Ten eerste: elk extern systeem werkt anders, en er is dus aparte code nodig voor elke pakketdienst waar ze mee willen integreren. Ten tweede slaat elk systeem tracking data op een andere manier op. Voordat ze dus iets met die data kunnen doen moeten ze het transformeren naar een uniform datamodel. Deze transformatiestap is ook weer specifiek voor elke integratie, en dat kan best een zware operatie zijn, helemaal als dit voor duizenden pakketten per seconde (zoniet meer) moet gebeuren. Voor dit alles hebben ze een extract-transform-load proces opgezet. Tijdens de extract stap worden externe systemen aangeroepen om tracking data op te halen, tijdens de transform stap wordt deze data omgezet naar het “Tracey-model”, en tijdens de load stap wordt de uniforme data in hun eigen database opgeslagen.
Voor
Voordat Tracey bij ons kwam hadden ze een relatief simpele opzet, waar een groot deel van de ETL pijplijn in één applicatie zat. Dat scheelde een stuk complexiteit, en zorgde ervoor dat nieuwe functionaliteit relatief snel opgezet kon worden. Schematisch zag dat er ongeveer zo uit:
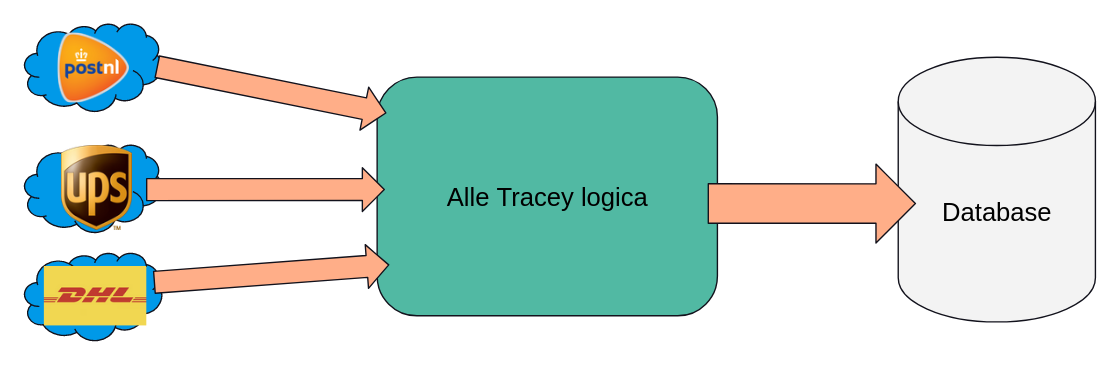
Met deze opzet liepen ze nu tegen de eerder genoemde problemen aan: de performance was niet goed genoeg meer om alle pakketten bij te houden, en er zat te veel code in één applicatie om het goed onderhoudbaar te houden.
De oplossing
Wat we hier zagen leek ons een perfecte kandidaat voor een microservice-architectuur. Als je kleine losse applicaties (microservices) maakt van elk stukje extractie- en transformatie-logica kan je deze los van elkaar opschalen wanneer je meer performance nodig hebt, en hou je alles qua code een stuk overzichtelijker. Deze services kan je vervolgens met elkaar laten communiceren via een message broker zoals RabbitMQ.
We hebben hier specifiek voor RabbitMQ gekozen om een aantal redenen. Het is heel eenvoudig op te zetten, het geeft je out of the box al een aantal interessante inzichten in de hoeveelheid berichten die er door het systeem gaan, en het schaalt ontzettend goed.
Zo gezegd, zo gedaan. Het resultaat is dat we de architectuur onder handen hebben genomen, om er dit van te maken:
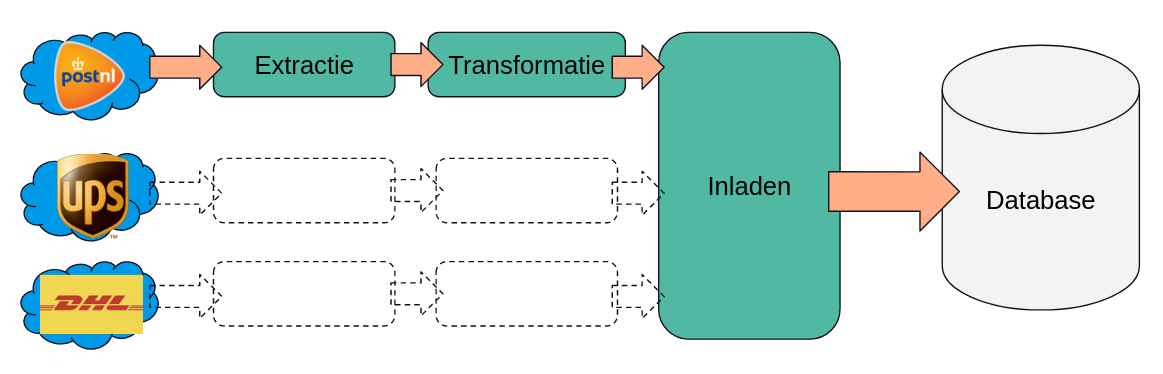
Zo is er een losse service om met het externe systeem van elk pakketbedrijf te integreren, en vervolgens een losse service om elk soort data om te zetten naar het interne model. Deze data inladen in de database is een relatief lichte operatie, dus dat is iets wat nog wel gewoon door een gedeelde service kan gebeuren. Met deze architectuur wordt de code niet alleen beter onderhoudbaar, maar kunnen ze ook zorgen dat losse extractie- of transformatie-services opgeschaald kunnen worden wanneer dat nodig is.
Altijd microservices?
Zoals ook al in de intro genoemd: hoe cool deze oplossing ook is, het is niet altijd de juiste oplossing, en er zitten ook een aantal nadelen aan. Het grootste nadeel is dat de architectuur er een stuk complexer door wordt, en je veel meer losse applicaties hebt die je draaiende moet houden. Ook is een service (automatisch) opschalen wanneer dat nodig is niet altijd even eenvoudig. Echter, in het geval van Tracey was het een goed passende oplossing waarmee in ieder geval de eerste grote drempel naar opschalen overwonnen is.
Wil je meer weten over Tracey en wat we samen gedaan hebben? Lees dan onze klant case!


