Performance problemen analyseren met Elastic APM
In deze blog laten we zien hoe je performance problemen kunt analyseren met Elastic APM. We laten zien hoe je de agent installeert en configureert en hoe je verder Kibana gebruikt om tot de oorzaak van performance problemen te komen. We tonen ook hoe je met behulp van proactieve monitoring fouten kunt vinden voordat gebruikers dat doen.
Installatie
De basis-installatieprocedure is heel eenvoudig. Je start met het installeren van de juiste afhankelijkheden. Vervolgens moet je in een regel een Elastic agent starten en configureren met informatie over jouw Elastic cluster.
Wij hebben zelf Elastic APM toegepast op onze interne portal Joost. Omdat wij gebruik maken van een NestJS backend doen we dit met behulp van Node en TypeScript:
Installatie agent
De afhankelijkheden installeer je als volgt met de node package manager:
npm install --save elastic-apm-node npm install --save-dev @types/node
Vervolgens zie je ze in jouw package.json:
"dependencies": {
"elastic-apm-node": "^4.0.0",
...
"devDependencies": {
"@types/node": "^20.6.0",
...
De elastic-apm-node package is verplicht. De @types/node package is om tijdens development in een vroeg stadium al fouten te krijgen aan de hand van de types.
Configuratie agent
De configuratie van de agent kan op een aantal manieren, maar als je Docker gebruikt is het voor de hand liggend om environment variabelen te gebruiken. Daarmee voldoe je ook aan de richtlijnen van de The Twelve-Factor App. Deze kun je configureren in bijvoorbeeld:
- Gitlab: Settings > CI/CD > Variables
- Mac: ~/.zshrc:
Environment variabelen
ELASTIC_APM_SERVICE_NAME=joost ELASTIC_APM_SECRET_TOKEN=xxxxxxxxxxxxxxxxxx ELASTIC_APM_SERVER_URL=https://82x6573d586644c98x538d89xx862xxx.apm.westeurope.azure.elastic-cloud.com:443 ELASTIC_APM_ENVIRONMENT=development
Hierbij is de service name een logische naam voor de service, de token voor authenticatie, de URL is de URL van je APM server en voor environment geef je jouw OTAP omgeving aan.
Performance problemen analyseren
- Genereer wat data door rond te klikken in de applicatie waarvoor je APM hebt geactiveerd.
- Vervolgens kun je performance problemen analyseren. Je begint met het inloggen op Kibana en ga dan naar: Observability > APM.
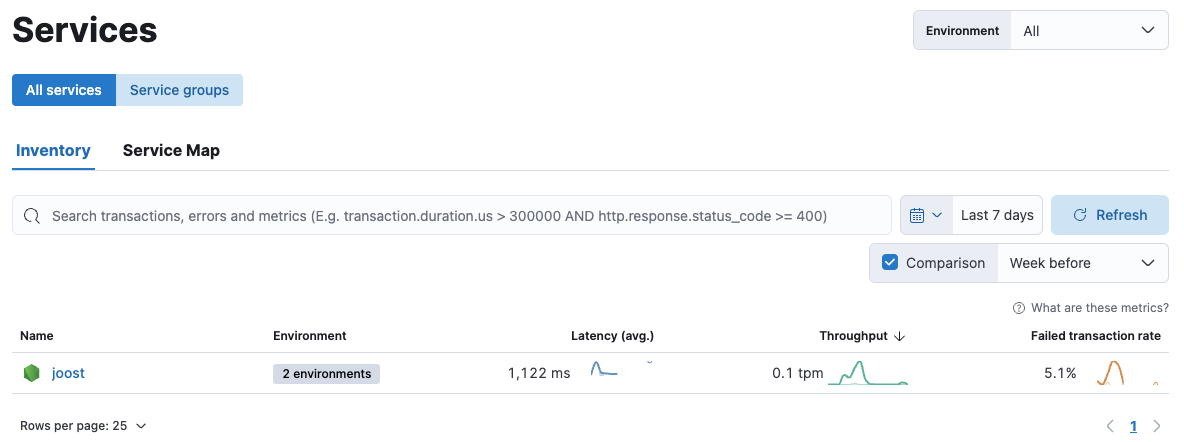
Daar vind je de service waarvoor je data hebt gegenereerd, geconfigureerd met ELASTIC_APM_SERVICE_NAME. In ons geval joost. Als je je muis plaatst boven de environment zie je daar ook de verschillende omgevingen waarvoor dat wordt gedaan geconfigureerd met ELASTIC_APM_ENVIRONMENT. In ons geval development, test.
Belangrijk hierbij is dat alle data die je ziet reageert op de tijd die je rechtsboven instelt. Dit kun je in Kibana op elk scherm instellen.
Alleen als er opgeslagen data is binnen de tijd die je hebt ingesteld wordt hier een service getoond.
- Klik op de service om een overzicht van de relevante metrieken te zien.
- Analyseer de transactions. Deze zijn gesorteerd op impact, wat een verhouding is tussen de avg. latency (responsetijd) en hoe vaak deze call is uitgevoerd, de throughput.
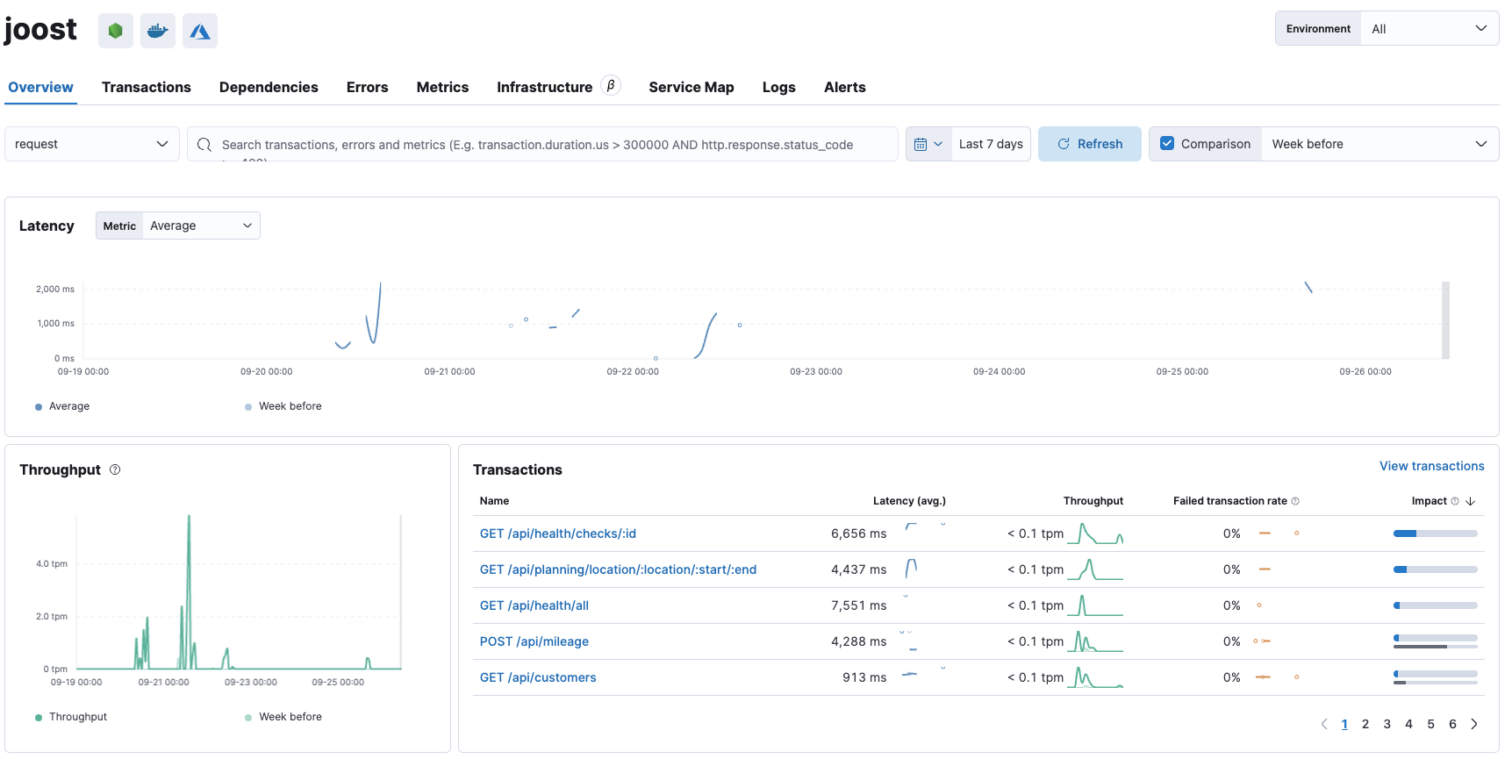
- Selecteer de transactie met de hoogste latency:
GET /api/health/checks/:id
- Analyseer de trace. Wat ons opvalt is dat er synchroon meerdere requests naar Microsoft worden gedaan en een request naar sharepoint, maar dat de vertraging zit in het stuk daarvoor.
- Open de bijbehorende code.
- In ons geval zien we daar een geïntroduceerde vertraging door een setTimeout:
@Get('/checks/:id')
public async getHealthCheck(@Param('id') id: string): Promise<HealthCheckDto> {
await new Promise((f) => setTimeout(f, 7000));
const file = await this.fileService.getFileContentsString(id);
return this.healthService.parseHealthCheck(file);
}
Fouten analyseren
Standaard zal de Node.js agent exceptions die niet zijn opgevangen automatisch naar Elastic APM sturen. Maar, in de meeste gevallen worden excepties niet gegooid, maar teruggegeven via een callback die wordt opgevangen door een Promise, of handmatig wordt gecreëerd.
We kunnen daarom in NestJS eenvoudig een interceptor toevoegen om dit alsnog te doen:
import { Injectable, NestInterceptor, ExecutionContext, CallHandler, HttpException } from '@nestjs/common';
import { Observable } from 'rxjs';
import { catchError } from 'rxjs/operators';
import apm from 'elastic-apm-node';
@Injectable()
export class ErrorInterceptor implements NestInterceptor {
private readonly apm: apm.Agent;
constructor() {
this.apm = apm;
}
intercept(context: ExecutionContext, next: CallHandler): Observable<Response> {
return next.handle().pipe(
catchError((error) => {
if (error instanceof HttpException) {
this.apm.captureError(error.message);
} else {
this.apm.captureError(error);
}
throw error;
})
);
}
}
In deze interceptor wordt de gehele verwerking van het request doorgezet naar de volgende stap in de pipe en als er een error is wordt deze geregistreerd met behulp van de APM API.
Vervolgens introduceren we een fout door een Error te gooien vanuit een endpoint:
@Get('weather')
getWeather(): WeatherDto[] {
throw new Error('Weather issues!');
return this.homeassistantAdapter.weather;
}
Als we ervoor zorgen dat dit endpoint wordt uitgevoerd, dan zien we in APM het volgende terug:

Hiermee is direct inzichtelijk welke errors optreden en hoe vaak.
Klik vervolgens op de Error die je wilt analyseren. In ons geval is dat Weather issues!
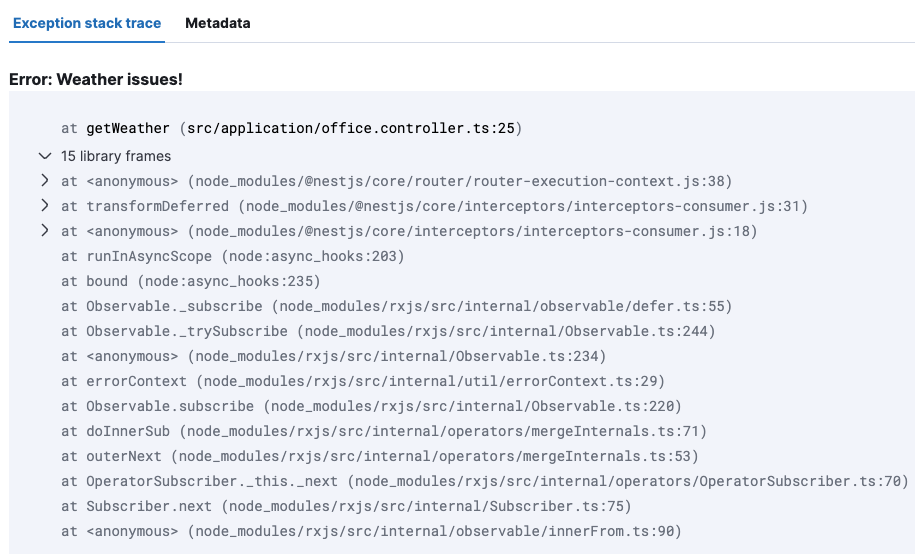
Vervolgens zie je de stack trace en kun je beginnen met het oplossen van de Error.
Proactief monitoren
Naast het bekijken van performance problemen of fouten in Kibana, kun je ook proactief monitoren. Hiermee voorkom je dat de beheerders niet pas ’s nachts uit bed worden gebeld, maar direct op de hoogte worden gesteld van een fout.
Dit kan bijvoorbeeld door een alert te definiëren en aan de hand hiervan een notificatie te laten versturen. Dit doe je als volgt:
- Ga naar: Observability > Alerts.
- Hier zie je alle alerts die daadwerkelijk zijn opgetreden. Als er nog geen rules voor zijn, zal deze lijst leeg zijn.
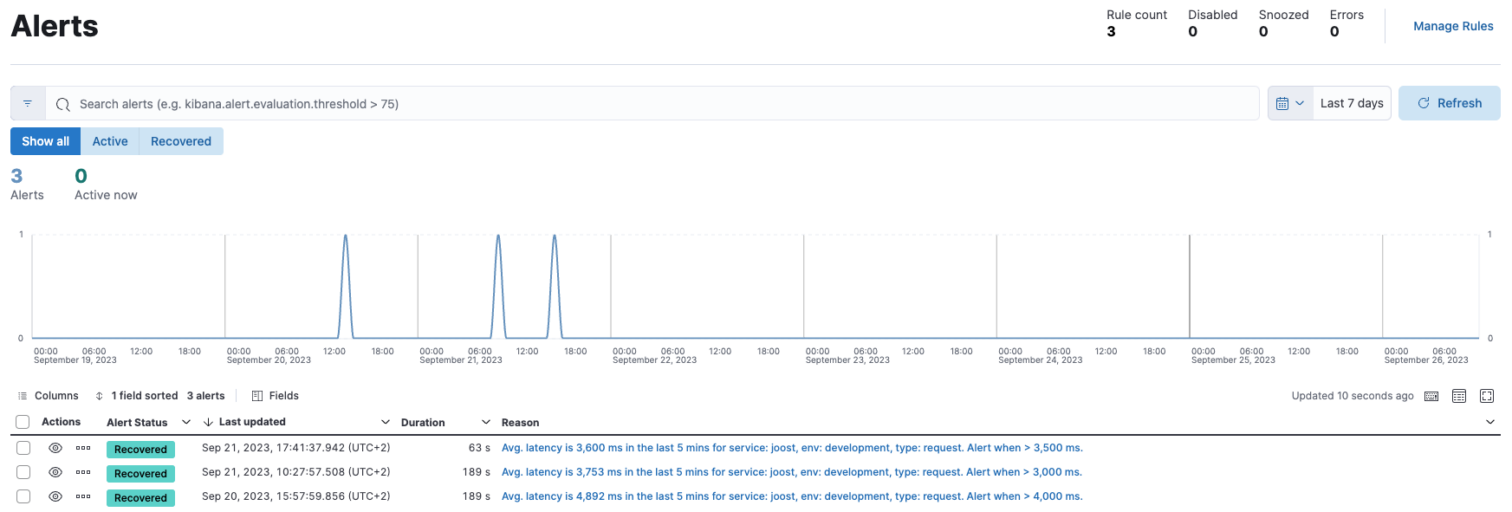
- Klik op Manage Rules
- Klik op Create Rule
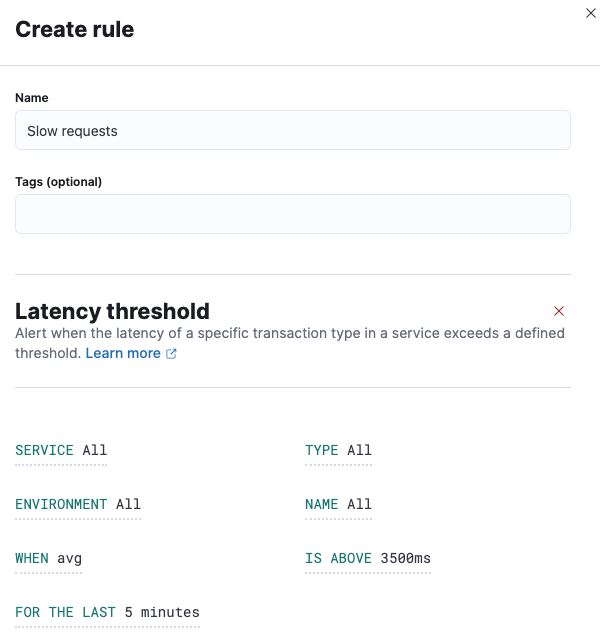
- Geef de rule een naam, bijvoorbeeld: Slow Requests
- Kies een rule type, bijvoorbeeld: Latency Treshold. Deze wordt getriggerd als een transactie een langere latency heeft dan de ingestelde waarde.
- Selecteer een bovenwaarde, bijvoorbeeld: 3000ms.
- Kies onder Actions een connector type, bijvoorbeeld: Email
- De action frequency staat standaard op On status changes. Dat betekent dat een alert alleen wordt verstuurd nadat het probleem optreedt, en niet iedere minuut waarop dat wordt gecontroleerd. Dat laatste zou ook kunnen, door te kiezen voor de waarde On check intervals.
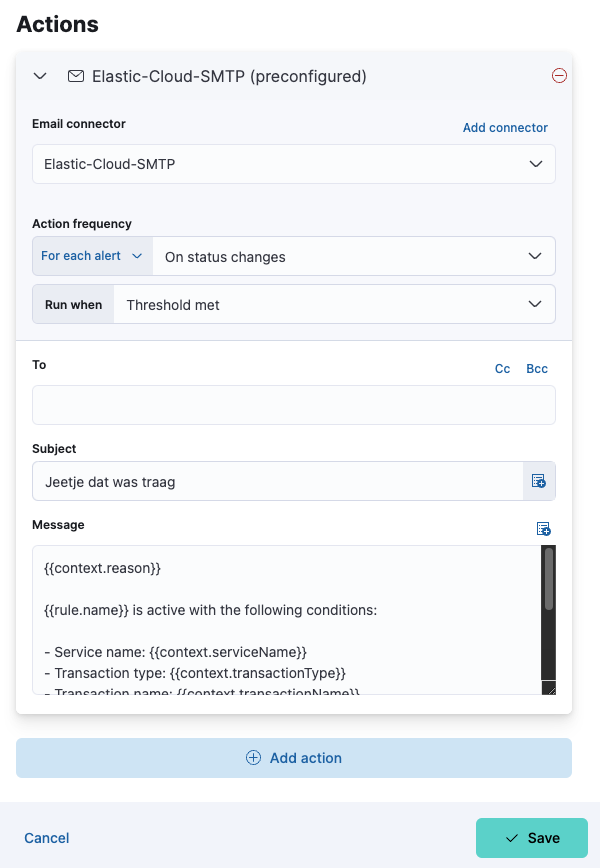
- Geef een subject aan die je in de mail terugziet en een message. Wij gebruiken het standaard bericht, dat op basis van wat placeholders dynamisch wordt aangemaakt.
- Klik save en je alert is actief.
Testen
Dit kan als volgt worden getest:
- Voeg een setTimeout toe aan de afhandeling van een request, zoals we eerder hebben gezien bij Performance problemen analyseren.
- Trigger een aantal keer het betreffende request zodat de gemiddelde latency boven de ingestelde treshold van 3500ms uitkomt.
- Wacht maximaal de standaard interval van 1 minuut.
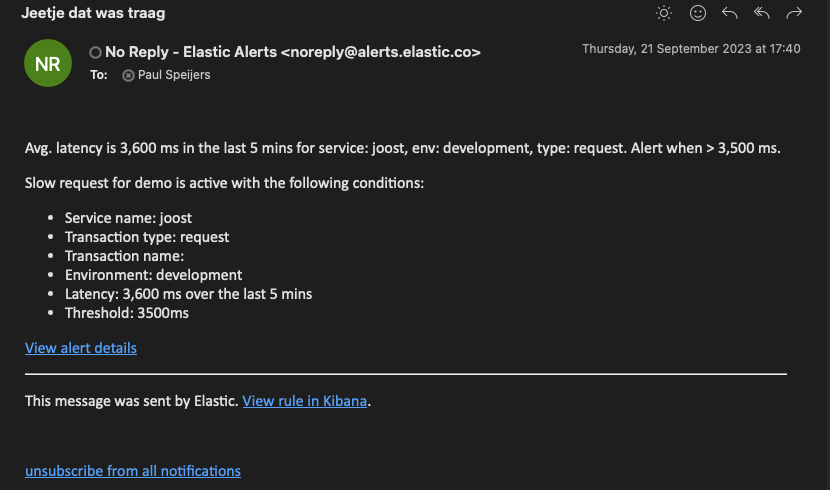
- Ontvang een email die er bijvoorbeeld zo uit ziet:
Ervaringen
Van de installatie van de agent tot en met het analyseren van performance problemen en fouten werkte allemaal vrij intuïtief. Je moet wel even gewend raken aan de concepten die worden gebruikt, maar die zijn over het algemeen goed gedocumenteerd door Elastic. Waar we nog het langste over hebben gedaan is uitzoeken wat de beste manier was om de agent te activeren. Toen dat echter eenmaal gedaan was konden we vrij snel het dashboard gebruiken. Ook was het even zoeken waarom Errors niet standaard worden gelogd, maar dat blijkt technische redenen te hebben. Al met al zijn er een paar weetjes, maar het was een goede ervaring met een krachtig platform.
Samenvatting
In deze blog hebben we getoond hoe je monitoring kunt opzetten door een agent te installeren en te configureren. Met behulp van een trace zijn we tot de bron van een performance probleem gekomen en we hebben ook getoond hoe je fouten kunt analyseren. Ook weet je nu hoe je alerts opzet om daarmee proactief te monitoren. Wij konden hiermee met niet al te veel moeite aan de slag en vonden het een krachtig platform.
Bronnen
De volgende bronnen zijn gebruikt in deze blog:
- https://www.elastic.co/guide/en/apm/agent/nodejs/current/express.html
- https://discuss.elastic.co/t/nodejs-agent-nestjs-and-typeorm/164171
- https://nestjs.com/
- https://www.docker.com/
- https://12factor.net/
Wil je ons meer vragen over APM monitoring op basis van Elastic? Of kunnen we je helpen bij het opzetten hiervan? Dan weet je ons te vinden!