Schalen in drie dimensies – deel 3: Logging en dashboarding
Schaalbaarheid van applicaties is een lastig probleem, en ook iets wat vaak niet één oplossing heeft. In dit laatste deel gaan we kijken naar meetbaarheid, want je kan pas echt iets zeggen over je schaalbaarheid als je harde getallen (en mooie grafiekjes) hebt.
Bij Infi hebben we een aantal projecten gedaan waar we tegen limieten aanliepen van wat de bestaande code en architectuur aankon, maar daar ook altijd mooie oplossingen voor bedacht. Hoe we dat gedaan hebben, en wat we daarvan geleerd hebben lees je in deze serie blogposts.
Meet: NPO-id
NPO-id is een product van de Nederlandse Publieke Omroep wat zorgt voor authenticatie en authorisatie voor alle diensten van de NPO, waaronder NPO Start en NPO Luister. Hier zitten gegevens in van ruim 1.1 miljoen accounts. Elke dag komen er meer dan 2000 nieuwe accounts bij, en proberen er tienduizenden mensen in te loggen.
De uitdaging
NPO-id is een kritiek stukje infrastructuur, want als dit niet werkt kan niemand meer gebruik maken van alle andere diensten. Bovendien gaat het hier om gevoelige informatie van gebruikers. Het is dus extreem belangrijk dat we in de gaten houden of dingen blijven werken, of de responstijden laag genoeg blijven, en of we niet gehackt worden!
De aanpak
Hoe begin je met zulke inzichten te krijgen in je systeem? Heel. Veel. Logging, metrics verzamelen, en dashboards maken. Hier is het direct goed om specifiek in te gaan op logging, want dat is niet per sé zo simpel als het klinkt. Als je namelijk iets simpels als “Gebruiker X logt in” wegschrijft naar de console of een log-bestand loop je in productie-scenario’s tegen twee problemen aan. Ten eerste is het lastig (of soms zelfs niet mogelijk) om op productie bij die logs te komen, en ten tweede is het moeilijk om de logs te doorzoeken.
Gestructureerd loggen
Deel van het probleem kunnen we oplossen door zo veel mogelijk informatie aan elke log-regel toe te voegen: waar komt een request vandaan, welke gebruiker gaat dit om, welke actie gebeurt hier, etc. Hierbij is het belangrijk om te zorgen dat deze informatie niet “zomaar” in de log staat, maar op een gestructureere manier, bijvoorbeeld als JSON. Zo kan een log-regel er bijvoorbeeld zo uit zien:
{
"message": "Gebruiker probeert in te loggen"
"timestamp": 1691573651,
"action": "login",
"user": {
"id": 123456
}
}
Zo heb je een “message” die eenvoudig door een mens te lezen is, en losse attributen die door een log management tool geïndexeerd kunnen worden. Zulke tools maken het eenvoudig om specifiek te zoeken naar bepaalde acties, berichten binnen een bepaald tijdsframe, of eigenlijk alles waar je een attribuut in je logs voor hebt.
Elasticsearch + Kibana = 📈
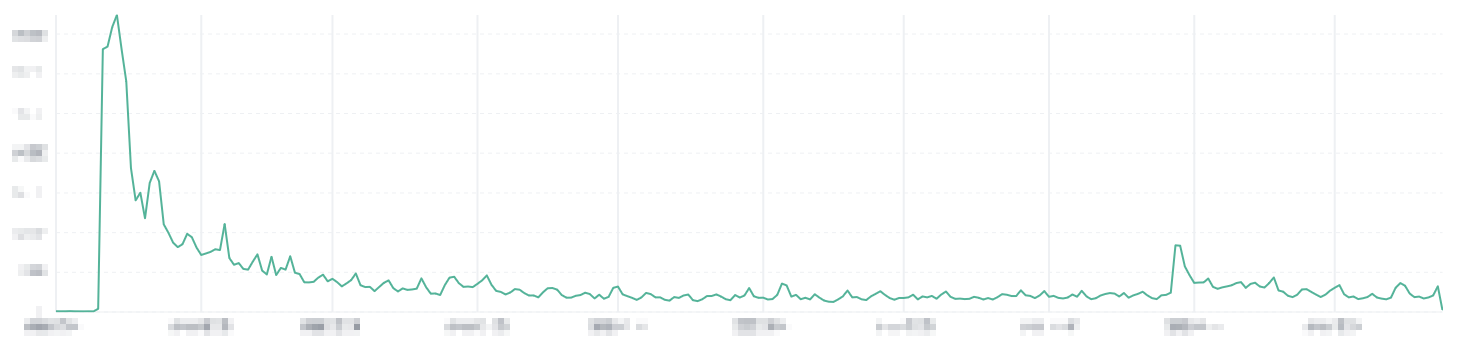
Om deze gestructureerde logs nu volledig te kunnen benutten is er Elasticsearch en Kibana opgezet. Elasticsearch wordt gebruikt om alle logs op te slaan en doorzoekbaar te maken, en Kibana wordt gebruikt voor allerlei interessante visualisaties. Zo kan je bijvoorbeeld een grafiek maken die toont hoeveel mensen er proberen in te loggen, en hoeveel van die pogingen succesvol zijn:
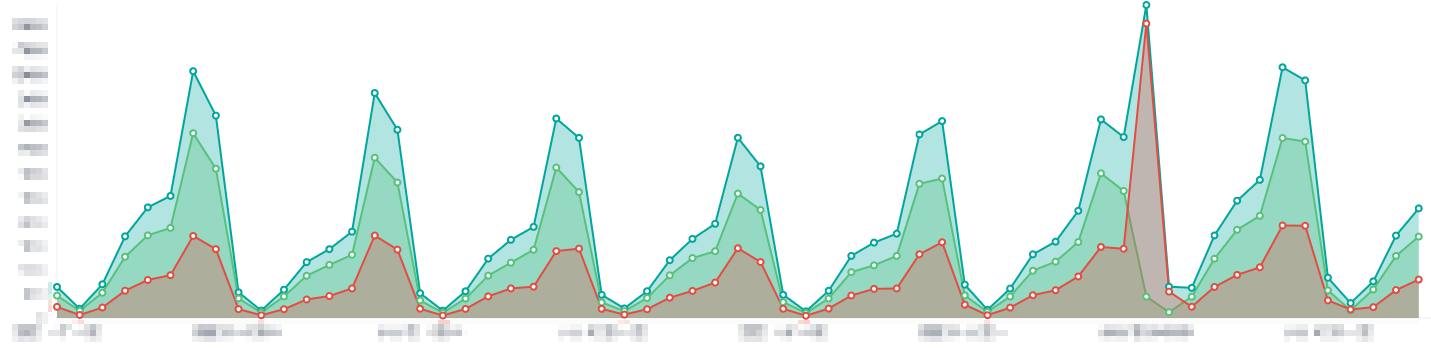
Met Kibana kan je een eenvoudig overzicht maken van wat er allemaal gebeurt in het systeem op een technisch niveau, maar je kan ook informatie verzamelen voor bijvoorbeeld KPI’s. Denk daarbij bijvoorbeeld aan het aantal nieuwe accounts per dag:
Hoe nu verder?
Met deze systemen, goede logs, en mooie dashboards is het natuurlijk niet ineens een gegeven dat er geen problemen meer zijn, of dat die snel opgelost kunnen worden. Het is belangrijk dat dit soort informatie en de dashboards iets is wat echt leeft binnen het project, anders is het een risico dat ze te weinig gebruikt worden om nut te hebben. Verder kan het soms lastig zijn om anomalieën – onregelmatigheden in de data – te identificeren, en zo te zien of er echt iets aan de hand is. Net als elk ander aspect van software-ontwikkeling is het zaak om hier continu verder op te bouwen, en te blijven verbeteren.