Schalen in drie dimensies – deel 2: Database clusters en load balancing
Schaalbaarheid van applicaties is een lastig probleem, en ook iets wat vaak niet één oplossing heeft. In deel twee van deze serie gaan we kijken naar databases: hoe maak je een applicatie waarvan je de code niet zelf schrijft toch schaalbaar?
Bij Infi hebben we een aantal projecten gedaan waar we tegen limieten aanliepen van wat de bestaande code en architectuur aankon, maar daar ook altijd mooie oplossingen voor bedacht. Hoe we dat gedaan hebben, en wat we daarvan geleerd hebben lees je in deze serie blogposts.
Meet: Bol.com
Bol.com heeft eigenlijk geen introductie meer nodig, aangezien het met afstand de grootste webshop van Nederland is. Om een idee te geven van de schaal waarop zij verkopen: ze hebben 35 miljoen artikelen, 52 duizend externe verkopers, en 13 miljoen actieve klanten (bron). Een van hun grootste uitdagingen is dan ook zorgen dat ondanks al dit webverkeer de website goed blijft werken, en voornamelijk: dat je snel kan vinden wat je zoekt.
De uitdaging
Voor veel mensen is het eerste wat je doet wanneer je bol.com opent iets invullen in de zoekbalk. Het zoekmechanisme is misschien wel het belangrijkste deel van de hele website: als je geen resultaten terugkrijgt, niet kan vinden wat je zoekt, of als het laden te lang duurt zal je minder snel wat kopen. Bol.com moet dus zorgen dat het doorzoeken van die 35 miljoen artikelen binnen een fractie van een seconde kan gebeuren – en dat continu voor vele duizenden gebruikers per dag. Hier komt ook nog bij dat de data van die producten regelmatig verandert: prijzen, beschrijvingen, categorieën, etc.
De naïeve aanpak
Wanneer je zo’n soort systeem simpel op zou zetten zou je waarschijnlijk een architectuur krijgen die hierop lijkt. Een database, een manier voor de website om daar zoekopdrachten op uit te voeren, en een manier voor verkopers om productupdates door te voeren.
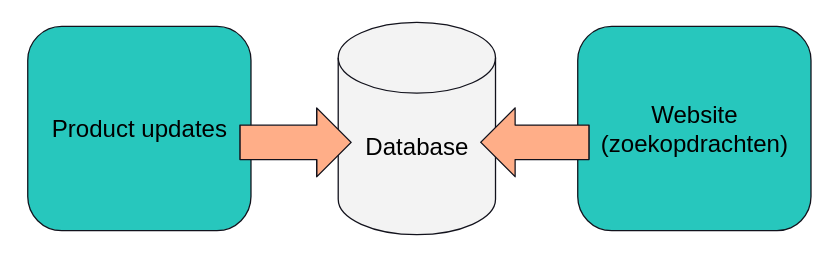
Echter, op de schaal van bol.com loop je hier tegen problemen aan. Er zijn namelijk zoveel producten en gebruikers, dat puur door de hoeveelheid en complexiteit van de zoekopdrachten ze aan het limiet zitten van wat de database aankan. Dit betekent dat productupdates niet doorgevoerd kunnen worden zolang er zoekopdrachten uitgevoerd worden.
In de praktijk staat hier ook niet één database, maar is dit eigenlijk een cluster van meerdere database servers. Hiermee kunnen ze het cluster mee laten groeien met de grootte van bol.com, en kunnen zoekopdrachten nog gewoon uitgevoerd worden als er een server uit het cluster uitvalt of stukgaat. Echter, ook met een cluster is de performance nog niet goed genoeg om updates en zoekopdrachten tegelijk aan te kunnen.
De schaalbare aanpak
Als zoekopdrachten en updates niet tegelijk op één cluster uitgevoerd kunnen worden ligt de oplossing stiekem misschien best voor de hand: zet een tweede cluster neer! Dit is natuurlijk simpeler gezegd dan gedaan: als je twee database clusters hebt moet je ook zorgen dat de product updates en zoekopdrachten naar het goede cluster gaan, en dat je de twee clusters kan omwisselen zonder een seconde downtime. Dit is hoe de (iets versimpelde) architectuur er dan uit komt te zien:
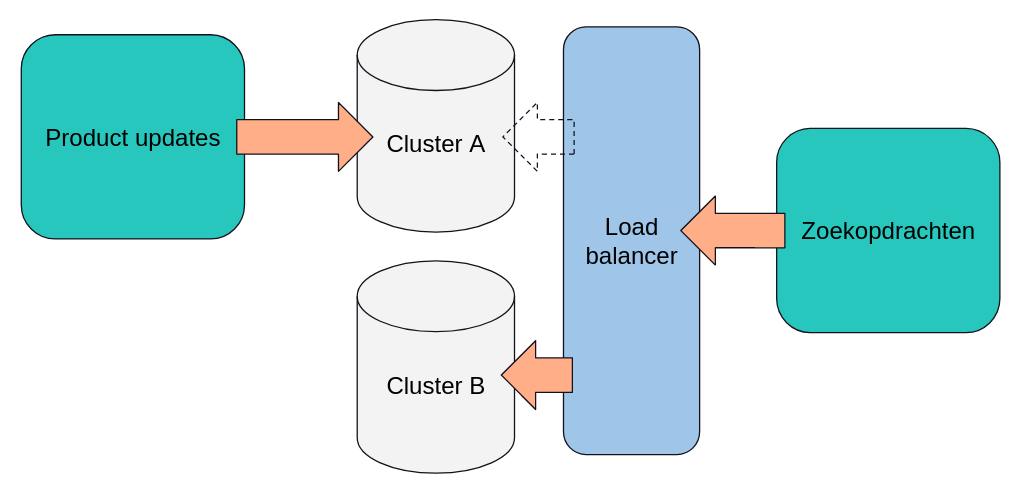
Er is naast het tweede cluster ook nog een ander component bijgekomen: een load balancer. Deze wordt gebruikt om te zorgen dat zoekopdrachten naar het goede cluster doorgestuurd worden, en dat het omwisselen van het cluster dat gebruikt wordt voor de zoekopdrachten geleidelijk kan gebeuren, door in stapjes steeds meer zoekopdrachten over te zetten naar het nieuwe cluster. Aan de andere kant worden continu productupdates op het andere cluster uitgevoerd. In de praktijk betekent dit dat die database helemaal opnieuw wordt opgebouwd op basis van de laatste productinformatie. Dit proces duurt dusdanig lang dat dit continu doorloopt, steeds op het andere cluster. Zodra de update van cluster A klaar is worden de zoekopdrachten naar cluster A gestuurd, en wordt cluster B opnieuw opgebouwd. Zodra dat klaar is worden de zoekopdrachten weer naar cluster B gestuurd, en wordt cluster A opnieuw opgebouwd, etc.
De menselijke factor
Met twee clusters komt bol.com al een heel eind, maar er is nog iets waar performancewinst te halen valt: de menselijke factor. Veel verschillende mensen zoeken namelijk op dezelfde termen, en het is zonde om voor elke zoekopdracht het cluster aan te spreken wanneer deze hetzelfde is als een zoekopdracht die eerder al eens is uitgevoerd. Om dit af te vangen kunnen we een cache bij beide clusters zetten waar alle zoekopdrachten en de bijbehorende resultaten in opgeslagen worden. Het architectuurdiagram komt er daarmee zo uit te zien:
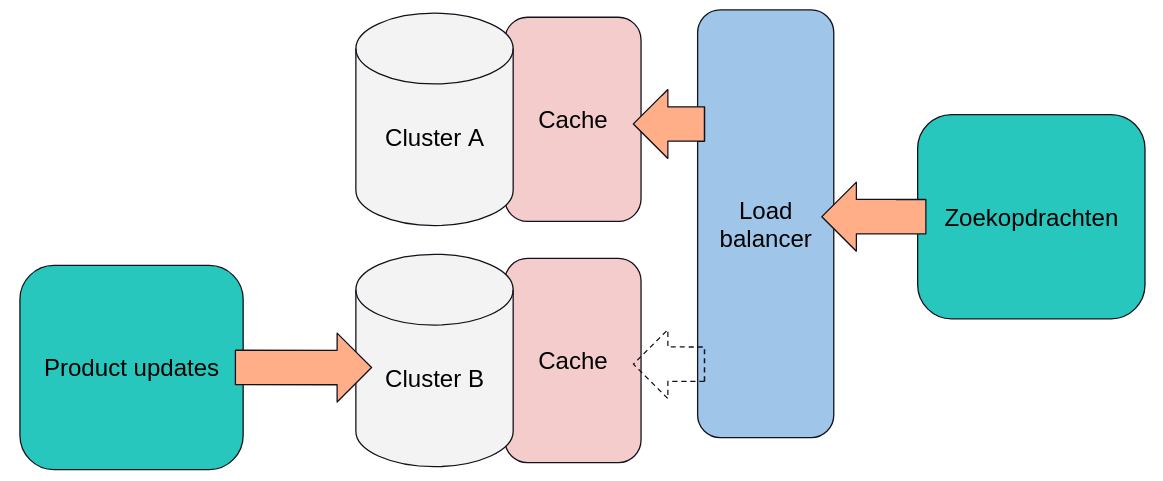
Als er nu een zoekopdracht van de site binnenkomt wordt eerst gecheckt of deze al in de cache voorkomt. Zoja, dan kunnen we het gecachte resultaat teruggeven zonder dat we daarvoor het cluster aan hoeven te spreken. Zoniet, dan wordt de zoekopdracht uitgevoerd op het cluster en het resultaat opgeslagen in de cache.
Goed genoeg?
Voor nu is deze opzet goed genoeg voor de hoeveelheid zoekopdrachten die bol.com moet verwerken. Echter, met hoe hard ze groeien is er geen garantie dat dit altijd voldoende zal blijven, en dan hebben we het nog niet eens gehad over de piekmomenten waarop extra veel besteld wordt. Dit is wel een schaal die ontzettend interessant is om op te werken, en die een hele eigen klasse aan uitdagingen en problemen met zich meebrengt. Een voorbeeld van zo’n uitdaging is hardware onderhoud, dat werkt op deze schaal heel anders. De SSD’s in de clusters worden bijvoorbeeld zo intensief gebruikt dat er bijna elke dag wel een stuk gaat. Gelukkig is dat iets waar we ons aan de software-kant niet te veel mee bezig hoeven te houden.